用大模型给模型开发与部署加点速度###
AI不一定会取代人类,但会用AI的人可能将会取代不会用AI的人。
让成年人焦虑的两大痛苦是工作和掉发,而如果一定要让两者结合起来,那就是程序员。作为一名程序员,每天大部分时间都在写代码、改bug,一般而言每天能写出一百多行有效代码,就算是高效的程序员了。不知道是不是为了在工作中,给大脑这个CPU加快散热,程序员往往跟头发不能共存。按照互联网能量守恒定律,代码量越大,头发掉得越多。反过来思考的话,代码量越小,头发掉得就越少。
为什么我们要关注程序员头发的问题,是因为大模型技术的出现,为保卫程序员的头发提供了生机。
史蒂夫乔布斯说:“人类是工具制造者,我们可以制造出将固有能力放大到惊人程度的工具。”
机器学习平台是开发算法模型必不可少的工具,百融云创打造了ORCA机器学习平台,其功能涵盖了一个模型从需求分析到算法开发、特征工程、模型训练、测试与优化、再到部署的全生命周期。
我们的研发团队再接再厉,引入大模型技术,在ORCA机器学习平台的基础上实现升级,打造了堪称模型开发加速器的ORCA-GPT。通过ORCA-GPT,开发者不仅能够以自然语言的方式生成代码,还能加速模型开发和部署的整个作业流程。
大模型助力三大节点提速增效
我们为什么要把大模型技术引入到ORCA机器学习平台?不光是为了程序员的头发,我们追求的还有建模的“速度与激情”。
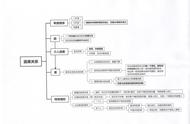
事实上,要开发部署一个AI模型并不简单,业内有人戏称,有多少人工才有多少智能。一个算法模型从设计、训练到部署,大致可分为以下八步,ORCA-GPT从三个环节上来实现“加速”。
加速数据预处理和特征工程
数据和特征决定了模型的上限,数据处理和特征工程占据了整个建模工程60%—70%的时间,这一过程带有浓重的手工业气息,需要耗费大量的时间和人力。
原始数据就像刚从地里开采出的石油一样,不能直接使用,需要一道“石油精炼”的环节,数据预处理就是一个“数据精炼”的过程。通过ORCA-GPT,只需要自然语言即可高效完成格式标准化、重复数据的去除,数值变量分箱和填充缺失值等工作,大幅提升数据处理的自动化能力,给AI准备好一份“整洁、漂亮和完整”的数据。

(缺失值补充)
特征工程的作用是从样本数据中提取最具代表性和有意义的特征,由此构建出对未知数据优秀的预测能力。比如一只猫的图片,我们从中提取嘴、尾巴、纹理、尾巴等特征,构建预测模型后,就能精准评定一张未知图片是否为猫。
ORCA-GPT具有自动化特征工程和特征衍生功能,开发者只需通过自然语言描述数据处理需求,ORCA-GPT就能够自动生成相应的代码,并返回给开发者进行确认和调整。
同时,ORCA-GPT还提供增益分析功能,帮助开发者评估每个特征对模型性能的贡献程度,从而指导开发者进行特征选择和优化,提升模型的预测性能。

(自动特征衍生)

(增益分析)
加速模型训练
模型训练是模型开发的核心环节。ORCA-GPT能提供自动模型训练功能,根据训练数据和目标变量,自动选择合适的算法和参数进行模型训练。在训练过程中,ORCA-GPT会实时输出训练进度和性能指标,帮助开发者了解模型的训练情况。训练完成后,ORCA-GPT还能够自动生成详细的模型报告,包括模型性能评估、特征重要性分析以及预测结果可视化等内容,为开发者提供全面的模型评估和优化建议。

(自动模型训练)
加速模型部署
模型部署是模型进入到业务场景最后一环。ORCA-GPT能提供灵活的模型部署方式,支持将Python脚本自动转换为ORCA方式部署,开发者只需上传模型文件,平台即可自动完成部署流程。此外,ORCA-GPT还提供模型服务上线功能,开发者可以将部署好的模型作为服务对外提供,实现模型的快速应用和推广。在实际应用中,最快不到一周的时间,即可完成从数据准备、模型训练、到模型部署的全流程。
在三个关键环节的加速下,ORCA-GPT能够显著减少模型开发过程中的人工干预和重复劳动,提高开发效率。同时还能大幅降低技术门槛,即使开发者没有深厚的AI技术能力,也能通过自然语言交互进行一些模型开发和部署工作。
目前,在百融云创内部ORCA-GPT已经得到了深度应用,在数据分析岗位上将建模时间缩短到30%。在某些实践中,之前需要 10 余人的工作,现在只需要 1-2 个算法人员即可搞定,并且通过大模型技术能够节约 90% 的推理成本。
目前公司内部新产生的代码中,有相当一部分是由AI自动生成,ORCA-GPT也在持续升级和加速中。